
One of the best ways of working out who is how many people are visiting your site, see patterns of traffic and analyse them over time is to look at your access logs.
Most web servers collect some form of access logs, mostly in a standard format such as the Common Log Format. As a CDN, CloudFront can also collect access logs when configured to do so, storing them in an S3 bucket ready for analysis.
resource "aws_s3_bucket" "cloudfront_logs_bucket" {
bucket = "cloudfront-logs"
lifecycle_rule {
id = "cloudfront_logs_lifecycle_rule"
enabled = true
expiration {
days = 365
}
}
}
resource "aws_cloudfront_distribution" "cloudfront_cdn" {
...
logging_config {
bucket = aws_s3_bucket.cloudfront_logs_bucket.bucket_domain_name
prefix = "main/"
}
...
}
Here, we set up CloudFront to save access logs to an S3 bucket, which we create with a lifecycle rule to make sure we’re not keeping logs forever.
Querying logs using SQL
The beauty of Athena is that it allows you to query any text files in S3 buckets using SQL. A perfect use for Athena is to pipe our access logs into it, and since we have a large volume of data, querying it using a familiar language built for those volumes is perfect.
First, we need to set Athena up:
resource "aws_s3_bucket" "cloudfront_logs_athena_results_bucket" {
bucket = "cloudfront-logs-athena-results"
lifecycle_rule {
id = "cloudfront_logs_athena_results_lifecycle_rule"
enabled = true
expiration {
days = 365
}
}
}
resource "aws_athena_database" "cloudfront_logs_athena_database" {
name = "cloudfront_logs"
bucket = aws_s3_bucket.cloudfront_logs_athena_results_bucket.bucket
}
resource "aws_athena_workgroup" "cloudfront_logs_athena_workgroup" {
name = "cloudfront_logs_workgroup"
description = "Workgroup for Athena queries on CloudFront access logs"
configuration {
enforce_workgroup_configuration = true
publish_cloudwatch_metrics_enabled = true
result_configuration {
output_location = "s3://${aws_s3_bucket.cloudfront_logs_athena_results_bucket.bucket}/output/"
encryption_configuration {
encryption_option = "SSE_S3"
}
}
}
}
We set up another S3 bucket which is used to cache the results of Athena queries. This makes them a lot faster, and importantly, means you don’t need to pay for the same query over and over again.
We then set up the Athena database and a workgroup, which is a way of separating different workloads and data sets.
So far, so good, but we still don’t have any data in Athena. We now need to create a table in the database that will contain the access log data.
resource "null_resource" "cloudfront_logs_athena_table" {
triggers = {
athena_database = aws_athena_database.cloudfront_logs_athena_database.id
athena_results_bucket = aws_s3_bucket.cloudfront_logs_athena_results_bucket.id
}
provisioner "local-exec" {
environment = {
AWS_REGION = eu-west-2
}
command = <<-EOF
aws athena start-query-execution --query-string file://templates/create_table_main.sql --output json --query-execution-context Database=${self.triggers.athena_database} --result-configuration OutputLocation=s3://${self.triggers.athena_results_bucket}
EOF
}
provisioner "local-exec" {
when = destroy
command = <<-EOF
aws athena start-query-execution --query-string 'DROP TABLE IF EXISTS cloudfront_logs.cloudfront_logs' --output json --query-execution-context Database=${self.triggers.athena_database} --result-configuration OutputLocation=s3://${self.triggers.athena_results_bucket}
EOF
}
}
Terraform does not currently support creation of Athena tables out-of-the-box, so we have to use the null resource with the local-exec provisioner, which is a way of executing arbitrary commands based on triggers. Here, we run the AWS CLI to execute a query which creates the table. We set up two triggers to execute this command when they change, and we also define a separate command to run on destroy which drops the table to clean up after itself.
The table creation is done with an SQL query in create_table_main.sql:
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs.cloudfront_logs (
`date` DATE,
time STRING,
location STRING,
bytes BIGINT,
request_ip STRING,
method STRING,
host STRING,
uri STRING,
status INT,
referrer STRING,
user_agent STRING,
query_string STRING,
cookie STRING,
result_type STRING,
request_id STRING,
host_header STRING,
request_protocol STRING,
request_bytes BIGINT,
time_taken FLOAT,
xforwarded_for STRING,
ssl_protocol STRING,
ssl_cipher STRING,
response_result_type STRING,
http_version STRING,
fle_status STRING,
fle_encrypted_fields INT,
c_port INT,
time_to_first_byte FLOAT,
x_edge_detailed_result_type STRING,
sc_content_type STRING,
sc_content_len BIGINT,
sc_range_start BIGINT,
sc_range_end BIGINT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\\t'
LOCATION 's3://cloudfront-logs/main/'
TBLPROPERTIES ('skip.header.line.count' = '2');
The fields are all the ones available in the CloudFront logs. We set the source location to the S3 bucket where CloudFront stores the logs, and ignore the header rows.
We now finally have all the bits we need to be able to query our logs. So we just need to go to the Athena console and run a sample query:
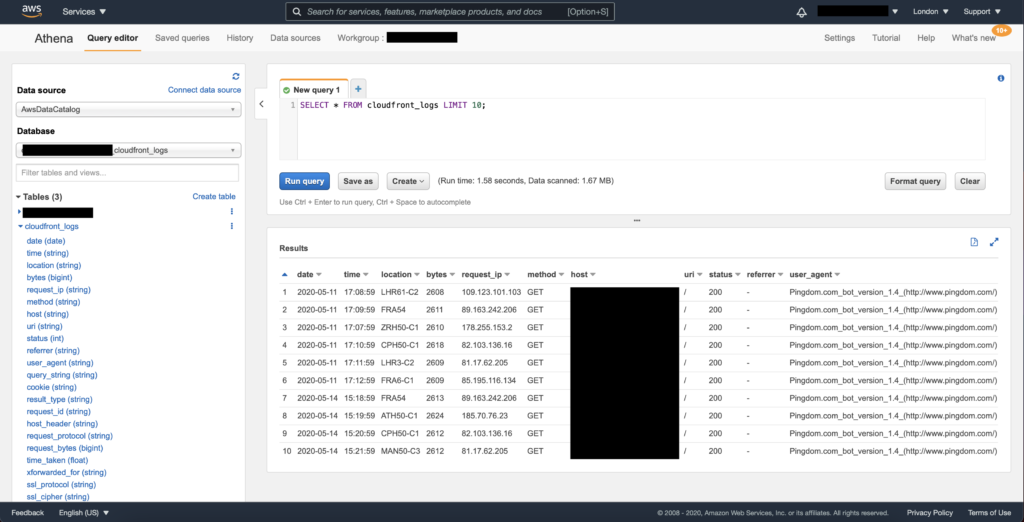
Here we’ve run a simple query to get the first 10 log entries. You can see that it took about 1.5 seconds and scanned about 1.67MB of data. These statistics are used to calculate how much you pay for the query.
Now everything’s set up, and we can run queries of any complexity to answer a particular question about visitors to our app quickly and easily.