
One of the tenets of modern framework-based web development is the management of your database state in code. Rather like infrastructure-as-code, it means there is an immutable history of the state of the application database at any point in time, which can be re-applied or rolled back as necessary. In addition, the desired state of the database and the application are tied together at any point in time to reduce the chances of divergence.
Part and parcel of having database migrations is being able to run them at the correct time during the deployment process. With classic deployment methods, this may just be a case of adding a migration command just before or after the deployment command.
However, if you’re using CodeDeploy with CodePipeline for your deployment, you’ll have noticed that there’s no built-in functionality for database migrations as part of deployment. That’s where the flexibility of CodePipeline comes into play.
CodePipeline to the rescue
CodePipeline by definition exists to bring together disparate parts of SCM, build and deployment into a single place. In practice, this flexibility means you’re free to add as many steps as you need in order to complete a deployment, in whichever order makes sense.
Normally, a minimal pipeline consists of a SCM source, a CodeBuild project that builds one or more artefacts, and a CodeDeploy project that deploys those artefacts to an AWS service (such as EC2 or ECS).
Given the flexibility of pipelines, and the fact that CodeBuild is basically a script runner, it’s trivial to add another CodeBuild project in the appropriate place that runs database migrations just before a CodeDeploy project deploys your code to staging or production.
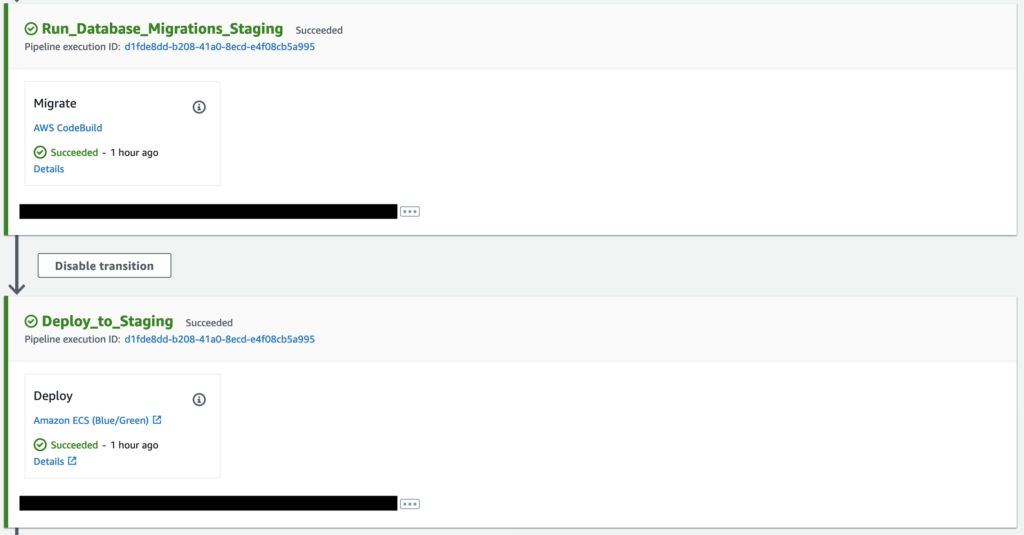
On our project, we have added a second CodeBuild project with a very small script that runs a single command to migrate the database to the latest version.
A one-off task for running migrations
Since we’re deploying to ECS using Fargate, we can make use of ECS task definitions to define a new task that will run our migrations for us. The reason for this is that the task will have all the context and access it requires to run the script, along with the latest version of the code that is about to be deployed.
We start by defining the task:
data "template_file" "app_db_migration_container_definition" {
template = file("templates/db-migration-container-definition.json.tpl")
vars = {
aws_region = var.aws_region
aws_environment = var.aws_environment
app_image = var.app_image
app_port = var.app_port
fargate_cpu = var.fargate_cpu
fargate_memory = var.fargate_memory
postgresql_host = var.postgresql_host
postgresql_username = var.postgresql_username
postgresql_password = data.aws_secretsmanager_secret_version.postgresql-primary_password.secret_string
postgresql_db_name = var.postgresql_db_name
redis_domain = var.redis_domain
rails_master_key = var.rails_master_key
}
}
data "template_file" "app_db_migration_task_definition" {
template = file("templates/db-migration-task-definition.json.tpl")
vars = {
container_definition = data.template_file.app_db_migration_container_definition.rendered
aws_environment = var.aws_environment
fargate_cpu = var.fargate_cpu
fargate_memory = var.fargate_memory
}
}
resource "aws_ecs_task_definition" "app_db_migration_task_definition" {
family = "staging-app-db-migration-task"
execution_role_arn = aws_iam_role.ecs_task_execution_role.arn
task_role_arn = aws_iam_role.ecs_task_role.arn
network_mode = "awsvpc"
requires_compatibilities = ["FARGATE"]
cpu = var.fargate_cpu
memory = var.fargate_memory
container_definitions = data.template_file.app_db_migration_container_definition.rendered
}
We have two data sources that define the contents of the task definition. Then we have the task definition itself that uses this data along with IAM roles to create an ECS task that we can run on demand.
The important thing to note here is that while this task definition is very similar to the one we use to run the actual app containers, this one is not part of an overarching ECS service. That means that it will not be run automatically, or restarted if it stops for any reason. This is desirable since we’re essentially using it in a throwaway fashion.
The actual content of the task definition should be very similar to whatever you have for your app containers, with one difference – the container definition will most probably have to override the default Docker command that you’ve defined in your Dockerfile:
"command": [
"bin/rails", "db:migrate"
]
This changes the default command to one that runs the database migrations. Once they’re run, the command will exit and will in turn bring the container down with it.
A CodeBuild project to run the one-off task
Now we have the task definition in AWS, we can go ahead and create a CodeBuild project to make use of it:
data "template_file" "codebuild_db_migration_buildspec_staging" {
template = file("templates/buildspec-db-migration.yaml.tpl")
vars = {
ecs_cluster = "staging-app-cluster"
ecs_task_definition = "staging-app-db-migration-task"
ecs_subnet_ids = join(",", data.terraform_remote_state.app_vpc_staging.outputs.private_subnet_ids)
ecs_security_groups = join(",", data.terraform_remote_state.app_security_groups_staging.outputs.sg_app_ids)
}
}
resource "aws_codebuild_project" "codebuild_db_migration_staging" {
name = "deployment-db-migration-codebuild-project-staging"
service_role = aws_iam_role.codepipeline_role.arn
artifacts {
type = "CODEPIPELINE"
}
cache {
type = "S3"
location = "${data.terraform_remote_state.infra_build_artifacts_bucket.outputs.build_artifacts_bucket_name}/codebuild-cache"
}
environment {
compute_type = "BUILD_GENERAL1_SMALL"
image = "accordodr/docker-19.03-dind:latest"
type = "LINUX_CONTAINER"
image_pull_credentials_type = "CODEBUILD"
privileged_mode = true
}
source {
type = "CODEPIPELINE"
buildspec = data.template_file.codebuild_db_migration_buildspec_staging.rendered
}
}
Here we create the CodeBuild project. We give it details of the ECS cluster and task definition to run as well as some network details that will be important later on.
The buildspec
The buildspec for the above CodeBuild project itself is:
version: 0.2
phases:
build:
commands:
- echo Build started on `date`
- echo Running database migrations...
- aws ecs run-task --launch-type FARGATE --cluster ${ecs_cluster} --task-definition ${ecs_task_definition} --network-configuration "awsvpcConfiguration={subnets=[${ecs_subnet_ids}],securityGroups=[${ecs_security_groups}]}"
- echo Build completed on `date`
As you can see, the buildspec is very simple. It just runs an AWS CLI command that kicks off the task definition we created above. For the Fargate launch type, a list of the VPC subnets and security groups connected with the ECS cluster need to be provided.
Adding this all to the pipeline
Now we have the task definition and a CodeBuild project that runs it, we just need to tie it all together by adding that project to our pipeline:
resource "aws_codepipeline" "codepipeline" {
name = "infra-codepipeline-pipeline"
...
# Build images, run automated test suite and push to ECR
stage {
name = "Build"
action {
name = "Build"
category = "Build"
owner = "AWS"
provider = "CodeBuild"
version = "1"
input_artifacts = ["source_output"]
output_artifacts = ["build_output"]
configuration = {
ProjectName = aws_codebuild_project.codebuild.name
}
}
}
# Run database migrations (staging)
stage {
name = "Run_Database_Migrations_Staging"
action {
name = "Migrate"
category = "Build"
owner = "AWS"
provider = "CodeBuild"
version = "1"
input_artifacts = ["build_output"]
output_artifacts = []
configuration = {
ProjectName = aws_codebuild_project.codebuild_db_migration_staging.name
}
}
}
# Deploy the image to ECS Fargate using a blue/green deployment system (staging)
stage {
name = "Deploy_to_Staging"
action {
name = "Deploy"
category = "Deploy"
owner = "AWS"
provider = "CodeDeployToECS"
version = "1"
input_artifacts = ["build_output"]
configuration = {
ApplicationName = aws_codedeploy_app.codedeploy.name
DeploymentGroupName = aws_codedeploy_deployment_group.codedeploy_deployment_group_staging.deployment_group_name
TaskDefinitionTemplateArtifact = "build_output"
TaskDefinitionTemplatePath = "taskdef-staging.json"
AppSpecTemplateArtifact = "build_output"
AppSpecTemplatePath = "appspec-staging.yaml"
}
}
}
}
Above is a sample pipeline that shows two CodeBuild projects – one that build the artefacts and one that runs the database migrations, followed by a CodeDeploy project that deploys the artefacts built earlier in the pipeline.
With this setup, you can always be sure that the database migrations have run before your application is deployed. If the migrations fail for any reason, the command will exit with a non-zero code, which will in turn exit the container with an error. CodePipeline is able to pick this up and stop the pipeline run with an error message.
What to remember when creating database migrations
You may have noticed that we run the database migrations before we deploy a new version of our application. We do this because the application will expect new or changed columns to be available when it starts running, and we don’t want a gap between the application being deployed and the migrations completing.
The astute amongst you will note, however, that this creates another issue – the database will change while the current version of the application is still running. In addition, if the deployment fails, this will become a permanent situation since the migrations are not rolled back.
For this reason, as well as being best practice, it is always advisable to create migrations in a way that means the application can keep running as intended with either the current or new database schema. In practice, this means:
- New columns can be added when required
- To delete a column, a version of the application that no longer expects it should be successfully deployed, followed by a second deployment to delete the column
- To rename a column, a column with the new name should be created along with a version of the application that uses it instead of the old name; once this is successfully deployed, a second deployment can delete the old column
By following the steps above, you can be sure that even if your deployment fails, your application will keep running.